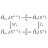理解 chatpdf.com 的代码原理
背景: 周末有个 chatgpt 比较火的应用 chatpdf.com 。主要功能是上传一个 pdf ,就能跨语言地和这个 pdf 对话(如果这个 pdf 是中文,可以用英文提问;反之也可)。根据这个 pdf 的内容回答你的问题。 这个应用很惊艳,打开了新世界的大门。
这个应用有很大的想象空间:
- 比如说这个 pdf 是国家的法律,那就可以问所有法律相关的问题。
- 如果这是图书馆里面的每一本书,那就可以对所有书对话。 ...
这个应用太优秀,有人在 twitter 上问作者用了什么原理,作者很大度,把大概原理说了一下。我自己挺好奇,第二天在一篇文章里看到有人开源了类似 产品 把代码下载看来一下,总结一下原理,我自己不是机器学习出身,可能谬以千里。
0 、openai 的 Embedding 接口
问了一下 chatgpt:
me: openai 的 embedding 是什么?
chatgpt: OpenAI 的 embedding 是一种将自然语言文本转换为向量表示的技术。
1 、文本切割
将文本切割成一小部分,调用 openai 的 embedding 接口,返回这段文本的 embedding 的向量数据。存储这些数据,并且保存好对应关系。
2 、用户提问
将用户提的问题,调用 openai 的 embedding 接口,返回问题的向量数据。
3 、搜索向量
计算相似度。用问题的向量,在之前切割的所有向量数据里,计算和问题向量相似度最高的几个文本(余弦定理)。
4 、调用 chatgpt
准备特殊的 prompt ,里面带上切割的文本内容,加上问题的 prompt 。
例子中的 prompt 是这样的:
const res = await fetch("https://api.openai.com/v1/chat/completions", {
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${apiKey}`
},
method: "POST",
body: JSON.stringify({
model: OpenAIModel.DAVINCI_TURBO,
messages: [
{
role: "system",
content: "You are a helpful assistant that accurately answers queries using Paul Graham's essays. Use the text provided to form your answer, but avoid copying word-for-word from the essays. Try to use your own words when possible. Keep your answer under 5 sentences. Be accurate, helpful, concise, and clear."
},
{
role: "user",
content: prompt
}
],
max_tokens: 150,
temperature: 0.0,
stream: true
})
});
以上就是这个应用的背后大概的原理。目前最大的限制是 chatgpt 接口的限制 4096 个 token 。我相信后面 openai 肯定会调整。
以上就是胡乱记录一下,如果有问题,欢迎纠正。